
Les statistiques et les probabilités dirigent le monde moderne ; elles sont partout, nous permettent de mieux comprendre le monde et surtout d’affirmer des prévisions plus ou moins souhaitable avec un dégrée suffisant de confiance. Dans le présent article, Jonas et Adrien présentent quelques études de probabilité.
Collectionneur de vignette :
Vous avez sûrement déjà entendu parler des cartes Pokémon, des collections de timbres et autre supercheries idolâtres. La question qui vient le plus souvent à l’esprit, c’est le temps et l’investissement nécessaire pour réussir une telle collection.
À cet exercice, vous pouvez compter sur les mathématiques et l’une de leurs branches les plus pratiques : les statistiques ! (Ne vous affolez pas, je vais essayer d’être le plus clair possible). Avant tout, posons le cadre dans lequel nous allons faire nos calculs : Colbert, notre avide collectionneur de carte Panini, obtient chaque jour au hasard de manière uniforme (tout résultats équiprobables) une parmi n carte Panini. Combien de jours cela prendra-t-il en moyenne pour que Colbert obtienne un exemplaire de chacune des cartes ?
Pour commencer, une tactique classique en mathématiques c’est de simplifier le problème et d’essayer d’en tirer une méthode plus générale : Imaginons d’abord qu’il n’existe que 2 cartes Panini à collectionner dans ce bas monde. Chaque jour, Colbert obtient l’une des deux, les statisticiens les plus avisés l’on bien reconnu, il s’agit d’une variable aléatoire géométrique.
L’économiste se contenterait surement d’user de la documentation afin de trouver l’espérance d’une telle variable aléatoire ; cependant c’est le travail d’un mathématicien de conforté des acquis : on va alors faire ce calcul de manière directe en passant par la définition de l’espérance pour une variable aléatoire discrète !
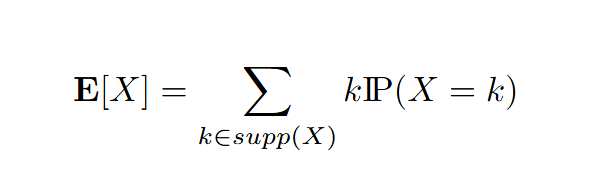
Pour rappel, voici la formule de l’espérance d’une variable aléatoire discrète où supp dénote le support de la variable aléatoire X.
Ici donc notre variable aléatoire X représente le nombre de jours que Colbert prend afin de terminer sa collection de deux vignettes. Impossible de finir sa collection en un jours, il a une chance sur deux de finir sa collection en deux jours (cela revient à ne pas piocher la même vignette deux fois) et une chance sur quatre finir sa collection en 3 jours (ne pas finir sa collection en deux jours et encore piocher la mauvaise vignette) et ainsi de suite, la formule de l’espérance s’écrit alors :
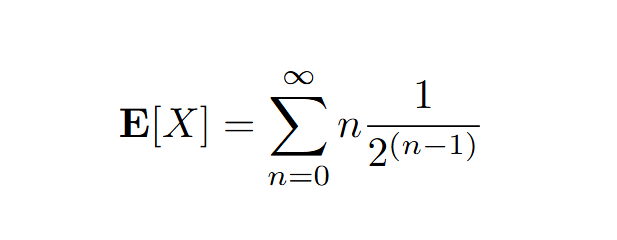
Et afin de calculer ceci, il faut utiliser une petite astuce en dérivant la formule que l’on connait pour la série géométrique (déjà vue dans le secondaire, mais je vous renvoie à un ancien mathém-article sur le paradoxe d’Achilles et de la tortue) on observe le suivant :
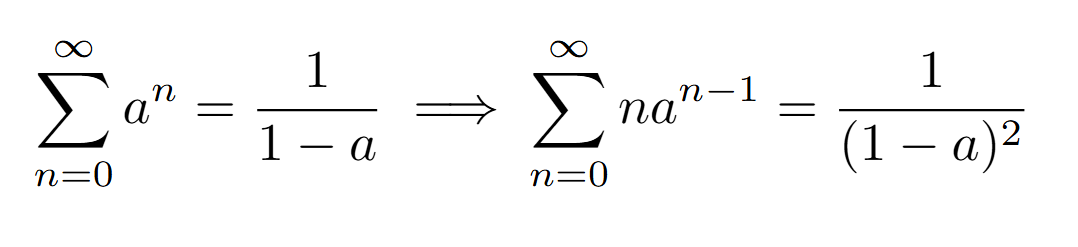 (Dérivation de la formule d’une série géométrique, cela est bien une opération légitime sur son domaine de convergence en tant que série entière)
(Dérivation de la formule d’une série géométrique, cela est bien une opération légitime sur son domaine de convergence en tant que série entière)
Et on reconnait facilement la formule de l’espérance que l’on essaie de calculer :
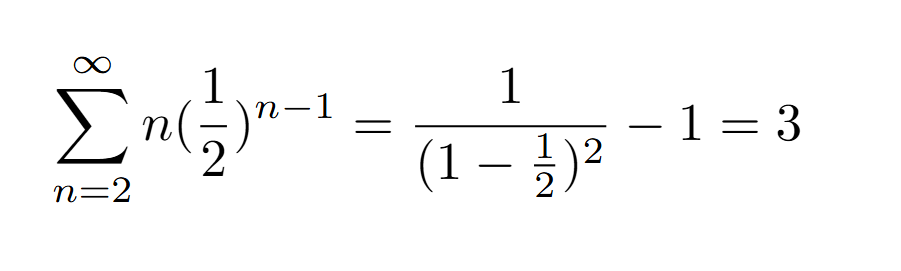
Colbert aura alors besoin de 3 jours en moyenne afin de compléter sa collection de deux vignettes. Maintenant pour le cas général à n vignette il nous faut découper le problème en plusieurs variables aléatoires Ti qui prendrons cette forme : on possède déjà i vignette, combien de jours pour trouver une nouvelle vignette parmi les n ?
Eh bien on voit que trouver l’espérances de chacune de ces variables aléatoires il s’agit à nouveau de loi géométrique et donc on peut simplement réutiliser la formule que l’on a vu précédemment. Et ainsi on peut “décomposer” le cas général en une somme de ces variables aléatoires Ti ce qui nous permet donc de calculer l’espérance du cas général grâce à la propriété de linéarité de l’espérance (je vous laisse vous convaincre de ce résultat en exercice) et on obtient le calcul suivant :
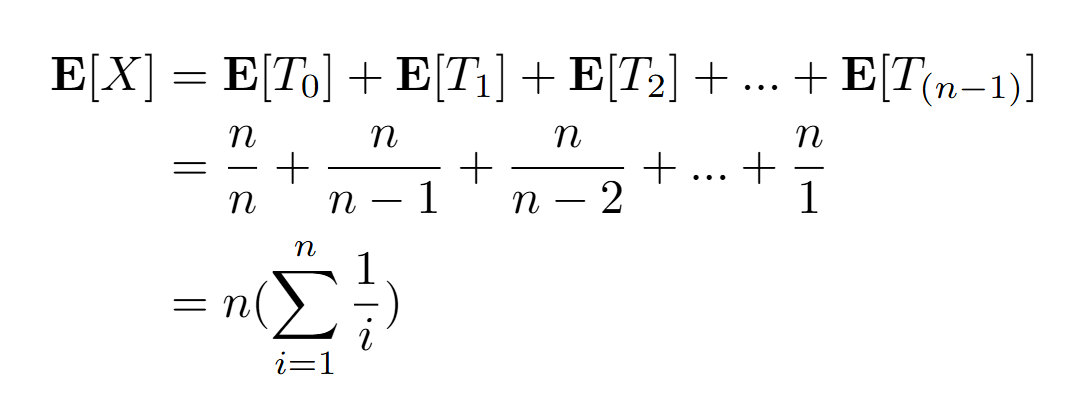 (Chaque variable Ti correspond à des variables aléatoires géométrique à probabilité uniforme selon son indice)
(Chaque variable Ti correspond à des variables aléatoires géométrique à probabilité uniforme selon son indice)
Et l’on remarque que c’est une formule particulièrement surprenante par son élégance, et qui en plus de cela fait apparaitre les termes de la “série Harmonique”. Afin de tester cette théorie par la pratique, on peut s’essayer à quelques expériences numériques et les figurer sur un graphique :
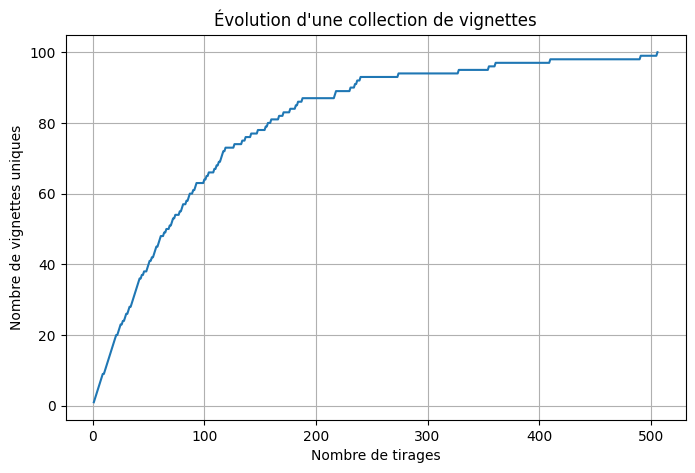
Supercherie de Variables aléatoires :
La loi Géométrique est sans mémoire
C’est le résultat le plus connu, à priori intuitif, mais une immense partie des gens (et moi y compris) se font toujours avoir par des raisonnements idiotiques : la fameuse erreur du parieur (en anglais Gambler’s fallacy). Pour mettre les choses au clair, dans le cadre d’une distribution de probabilité géométrique, ce qu’il s’est passé jusqu’avant le prochain lancé ne vaut rien et n’influence en rien le futur.
D’un point de vue pratique, si vous jouer régulièrement à la roulette, que les trente derniers résultats étaient rouges, cela ne signifiera en aucun cas que le prochain lancer a plus de chances d’être noir. Avec ce résultat en tête, vous pouvez garder l’esprit calme et jouer les yeux fermés. Si cet argument d’autorité ne vous a pas convaincu, afin de se persuader de ce résultat, voici un petit calcul :
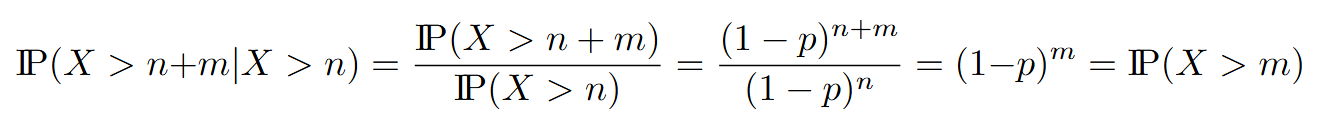
Sans trop donner de détails, car ce sont des calculs assez pédants, ce résultat peut initialement sembler du bon sens, mais il est toujours courant de tomber dans le panneau. Par exemple la supposée nuit du 18 aout 1913 au célèbre casino de Monte-Carlo, à la table de roulette, la bille serait tombée 26 fois d’affilée sur une case noire, mais les joueurs crédules misaient continument (à tort) sur les cases rouges en pensait qu’elles étaient plus probables.
Collider Bias et Berksons Paradox
Un des premières manières avec lesquelles on peut explorer des données, c’est de trouver des corrélations. Quiconque a pris un cours de statistique connait le dicton : “corrélation n’est pas causalité”. En réalité, la corrélation est plutôt une invitation à investiguer la causalité. Mais ici, on laisse l’inférence causale pour un future article et on se pose plutôt la question : pourquoi voit-on des corrélations si elles n’existent pas ?
C’est un enjeu important pour la société, parce que ces perceptions par la population, vraies ou fausses, forment souvent les croyances et opinions de la population. Le “paradoxe de Berkson” est un exemple d’une mauvaise perception qui crée une corrélation là où il n’y en a pas. Le paradoxe se base sur le “Collider Bias”, une sorte de biais de sélection. En essence, si deux variables influencent une troisième variable, et qu’on conditionne sur cette troisième variable, cela peut influencer la relation entre les deux premières.
Une application célèbre est le “Great Square of Men” de Jordan Ellenberg. Cela provient d’une observation générale des rencontres amoureuses où personnalité et attractivité semblent souvent être négativement corrélées. Ou autrement dit : les gens attractifs ont une mauvaise personnalité, confirmant un préjugé qu’on retrouve souvent en société.
Mais en fait, ce phénomène apparaît aussi dans une population dans laquelle il y a 0 corrélation entre attractivité et personnalité. Pour l’exemple du « Great square of (wo)men » : supposons qu’une personne choisisse des gens pour un rencard sur deux critères : l’attractivité et la personnalité. En plus, supposons qu’elle mesure ces deux valeurs sur une échelle de 1 à 10 et, parce qu’elle a des standards, va seulement rencontrer des gens qui ont une somme de personnalité et d’attractivité égale ou supérieure à 14. Donc elle va dater une personne qui a une personnalité de 10/10 même si elle trouve que la personne n’est pas vraiment attractive (4/10) et l’inverse. Ci-dessous, vous trouvez une image qui montre une population simulée (chaque point est une personne) où il n’y a pas de corrélation entre les deux variables. La ligne grise montre la relation entre attractivité et caractère de la population complète, c’est -0.0051, donc très légèrement corrélé négativement, mais la p-value est 0.611, donc cette relation n’est pas statistiquement significative.
Mais le fait que la perception soit conditionnée sur le fait que les gens sont dans le « dating pool » crée le « collider », où attractivité et personnalité influencent si quelqu’un est dedans ou non. Si on examine ce dating pool en bleu, on voit que les gens dedans peuvent compenser un « déficit » dans l’un des deux critères en ayant une forte valeur dans l’autre. Donc les personnes les plus attractives en moyenne ont une personnalité moins forte que ceux qui sont moins attractifs. Ça crée une corrélation là où il n’y en avait pas avant, quand on regardait la population complète.
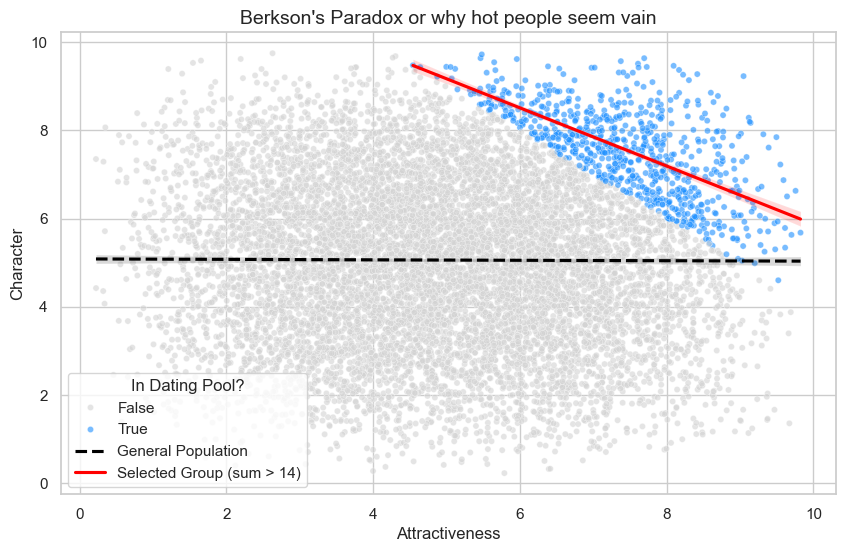
Ce phénomène apparaît souvent avec des populations qui forment un groupe très contraint. La perception qu’il existe une corrélation négative entre talent et amabilité (ou attractivité) chez les acteurs ou les musiciens relève du même mécanisme.
Un autre exemple frappant est celui des livres de niche, perçus comme excellents, mais dont la note moyenne chute lorsqu’ils deviennent populaires. Cela s’explique par deux mécanismes principaux qui nous poussent à lire. D’un côté, on aime certains types de livres, donc on lit des ouvrages similaires : il est alors très probable qu’on les apprécie. De l’autre, si un livre est populaire, on l’essaie simplement parce qu’il fait du bruit. Dans ce second cas, il est fréquent qu’on ne l’aime pas autant que les premiers lecteurs de la niche, ce qui fait tomber les appréciations.
Perdre pour gagner, ou bien le paradoxe de Parrondos
Dans les casinos, les jeux comme les machines à sous ou le craps ont une espérance négative. Cela signifie qu’à long terme, vous allez perdre, même si à court terme il est possible de gagner. L’hypothèse logique est que si on combine deux jeux avec une espérance négative, l’espérance combinée est aussi négative. Mais ce n’est pas toujours le cas !
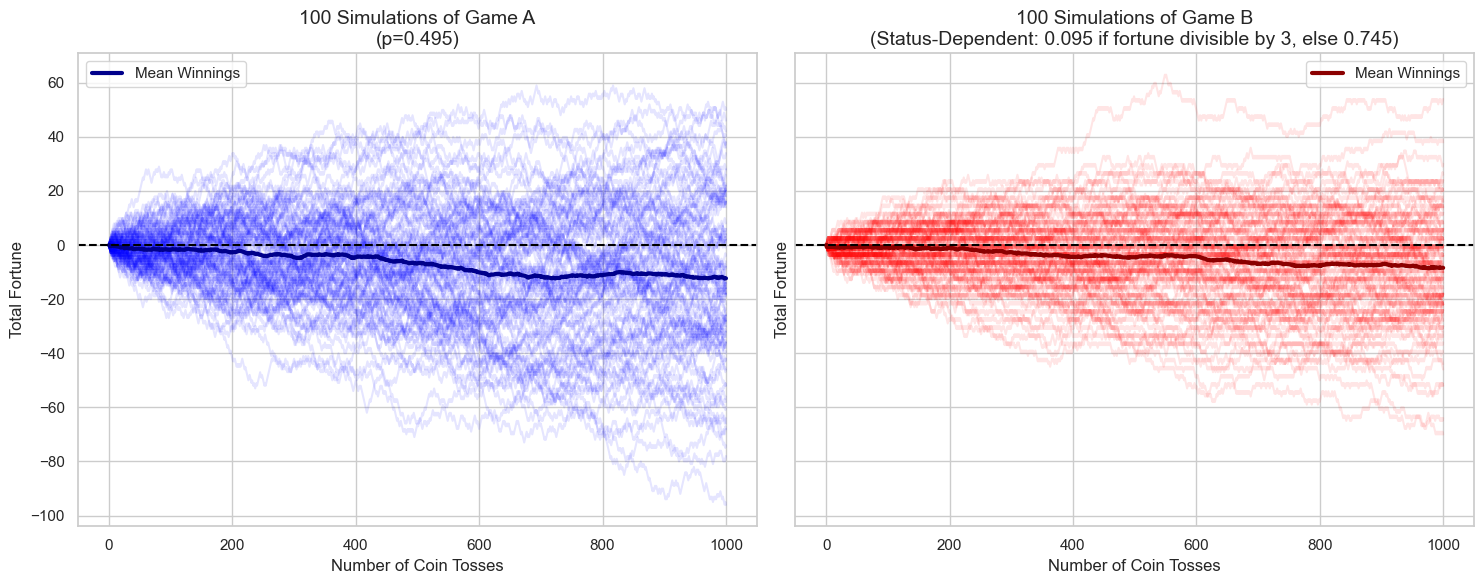
Imaginez deux jeux non favorables. Le premier est un pile ou face. Si vous gagnez, c’est +1 $, si vous perdez, –1 $. Mais la pièce est biaisée. La probabilité que vous gagniez est de 49,5 %. Donc l’espérance de ce jeu est de –0,01 $.
Le deuxième jeu est un peu plus compliqué. Il existe deux pièces avec des probabilités différentes. Et la pièce qui est utilisée dépend de la fortune, ou argent total, que vous avez. Quand votre fortune est divisible par 3 (donc 3, 6, 9, …), la chance de gagner est seulement de 9,5 %. C’est une espérance de –0,81 $. Mais si votre fortune n’est pas divisible par 3, la chance de gagner est de 74,5 %. Une espérance de +0,49 $.
Les maths pour calculer l’espérance complète de ce jeu sont trop chargées pour être montrées ici (l’utilisation des deux pièces du deuxième jeu est dépendante de la fortune totale, ce qui complique les maths), mais heureusement, il existe les simulations de Monte-Carlo afin d’approximer l’espérance.
Une manière d’expliquer l’espérance dans le contexte de ce jeu est le gain moyen si l’on joue au jeu une infinité de fois. Mais pour une approximation, il faut seulement simuler 100 parties, chacune avec 1 000 lancers de pièces. Cela nous sert de bonne approximation de l’espérance.
Pour le jeu numéro 1, après 1 000 lancers, on a en moyenne –10 $. L’espérance de chaque lancer individuel est de –0,01, donc fois 1 000, cela est égal à –10. Cela confirme le résultat mathématique. Pour le deuxième jeu, on saute les maths et on prend les résultats de la simulation : on voit que, comme pour le premier jeu, l’argent est négatif, autour de –10. Donc les deux jeux ont une espérance négative. Comme dans un casino normal, vous ne pouvez que perdre.
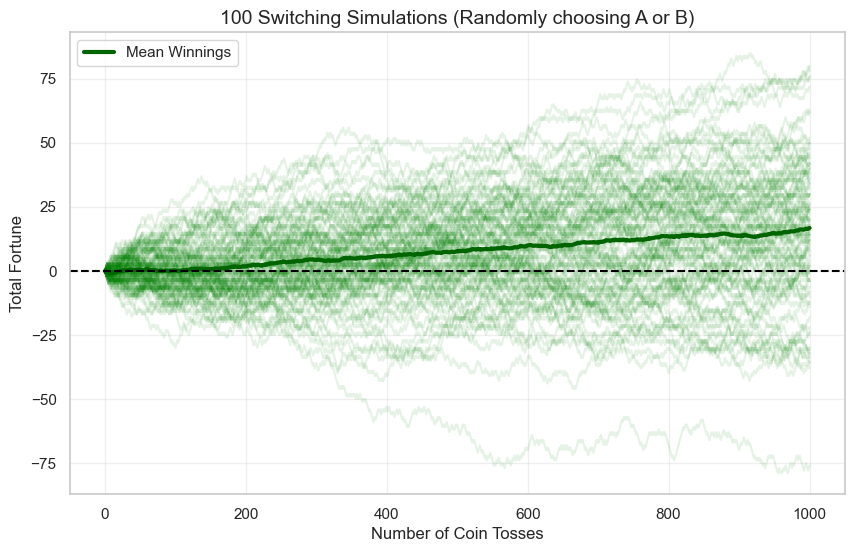
Mais non ! En fait, si on change aléatoirement entre les deux jeux (probabilité de 50 % de changer après chaque « flip »), on va gagner. La simulation en vert ci-dessous nous montre un gain positif. Comment cela est-il possible !?
La raison réside dans le fait que le chaos introduit par le changement aléatoire d’un jeu à l’autre fait que l’on peut dépasser le désavantage fort de la pièce avec laquelle on ne peut gagner que dans 9,5 % des cas. Donc si vous avez une fortune divisible par 3 et que vous êtes sur le jeu 1, avec une probabilité de 49,5 vous gagnez, et si vous changez après au jeu 2, la probabilité de gagner devient 74,5 %. Ce terrible changement de pièce permet de faire un gain positif avec une stratégie de positionnement aléatoire entre les deux jeux.
Une explication plus intuitive se trouve en sport. Faire le maximum de sport chaque jour n’est pas utile. Au contraire cela va probablement être un net négatif pour la santé et fitness parce que trop de sport est mauvaise pour le corps. À l’inverse, la stratégie de rester inactif chaque jour n’est pas efficace non plus. Seul un mélange entre le deux va mener à une augmentation de sa forme. Parce qu’avec un bon repos pour le corps on peut éviter les jours ou il est déjà si utilisé que cela ait un effet négatif lorsque l’on s’entraine.
Adrien Mocaer & Jonas Bruno
Sources :
Problème du collectionneur de vignettes
Code pour réplication sur GitHub
{kind=link}
Articles similaires :

Encore des mathématiques

The Sports Gambling Epidemic
